Doctrine 2 versus NotORM video tutorial
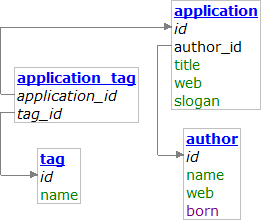
NotORM is a PHP library for simple working with data in the database. The most interesting feature is a very easy work with table relationships. The overall performance is also very important and NotORM can actually run faster than a native driver. NotORM for databases is like SimpleXML for XML documents.
NotORM provides a very intuitive API. Examples are showing the API on a simple database that is included in the download.
include "NotORM.php";
$pdo = new PDO("mysql:dbname=software");
$db = new NotORM($pdo);
NotORM uses PDO driver to access the database.
foreach ($db->application() as $application) { // get all applications
echo "$application[title]\n"; // print application title
}
Use a method call to get rows from the table. Use square brackets to access a column value.
$applications = $db->application()
->select("id, title")
->where("web LIKE ?", "http://%")
->order("title")
->limit(10)
;
foreach ($applications as $id => $application) {
echo "$application[title]\n";
}
The example gets first ten applications with HTTP URL ordered by a title.
$application = $db->application[1]; // get by primary key
$application = $db->application("title = ?", "Adminer")->fetch();
echo $application->author["name"] . "\n"; // get name of the application author
foreach ($application->application_tag() as $application_tag) { // get all tags of $application
echo $application_tag->tag["name"] . "\n"; // print the tag name
}
Simple work with relationships is a killer feature of NotORM. Method call ->() on a row object gets all rows from referencing table, member access -> stands for table referenced by the current row, and array access [] gets always a value in the row. Checkout the performance of this code.
// get all applications ordered by author's name
foreach ($db->application()->order("author.name") as $application) {
echo $application->author["name"] . ": $application[title]\n";
}
If you need to filter or order rows by column in referenced table then simply use the dot notation.
echo $db->application()->max("id"); // get maximum ID
foreach ($db->application() as $application) {
// get count of each application's tags
echo $application->application_tag()->count("*") . "\n";
}
All grouping functions are supported.
$db = new NotORM($pdo[, $structure[, $cache]]) | Get database representation |
$db->debug = true | Call error_log("$file:$line:$query; -- $parameters") before executing a query
|
$db->debug = $callback | Call $callback($query, $parameters) before executing a query, if $callback would return false then do not execute the query
|
$db->debugTimer = $callback | Call $callback() after executing a query
|
$db->rowClass = 'ClassName' | Derive row objects from this class (defaults to 'NotORM_Row')
|
$db->transaction = $command | Assign 'BEGIN', 'COMMIT' or 'ROLLBACK' to start or stop transaction
|
$table = $db->$tableName([$where[, $parameters[, ...]]]) | Get representation of table $tableName
|
$table->where($where[, $parameters[, ...]]) | Set WHERE (explained later)
|
$table->and($where[, $parameters[, ...]]) | Add AND condition
|
$table->or($where[, $parameters[, ...]]) | Add OR condition
|
$table->order($columns[, ...]) | Set ORDER BY, can be expression ("column DESC, id DESC")
|
$table->order("") | Reset previously set order |
$table->select($columns[, ...]) | Set retrieved columns, can be expression ("col, MD5(col) AS hash")
|
$table->select("") | Reset previously set select columns |
$table->limit($limit[, $offset]) | Set LIMIT and OFFSET
|
$table->group($columns[, $having]) | Set GROUP BY and HAVING
|
$table->union($table2[, $all]) | Create UNION
|
$table->lock($exclusive) | Append FOR UPDATE (default) or LOCK IN SHARE MODE (non-exclusive)
|
$array = $table->fetchPairs($key, $value) | Fetch all values to associative array |
$array = $table->fetchPairs($key) | Fetch all rows to associative array |
count($table) | Get number of rows in result set |
(string) $table | Get SQL query |
$table($where[, $parameters[, ...]]) | Shortcut for $table->where() since PHP 5.3
|
Repetitive calls of where, order and select are possible – it will append values to the previous calls (where by AND). These methods plus group and limit provide a fluent interface so $table->where()->order()->limit() is possible (in any order). All methods are lazy – the query is not executed until necessary.
The $where parameter can contain ? or :name which is bound by PDO to $parameters (so no manual escaping is required). The $parameters[, ...] can be one array, one associative array or zero or more scalars. If the question mark and colon are missing but $parameters are still passed then the behavior is this:
$table->where("field", "x") | Translated to field = 'x' (with automatic escaping)
|
$table->where("field", null) | Translated to field IS NULL
|
$table->where("field", array("x", "y")) | Translated to field IN ('x', 'y') (with automatic escaping)
|
$table->where("NOT field", array("x", "y")) | Translated to NOT field IN ('x', 'y') (with automatic escaping)
|
$table->where("field", $db->$tableName()) | Translated to "field IN (SELECT $primary FROM $tableName)"
|
$table->where("field", $db->$tableName()->select($column)) | Translated to "field IN (SELECT $column FROM $tableName)"
|
$table->where("field > ? AND field < ?", "x", "y") | Bound by PDO |
$table->where("(field1, field2)", array(array(1, 2), array(3, 4))) | Translated to (field1, field2) IN ((1, 2), (3, 4)) (with automatic escaping)
|
$table->where(array("field" => "x", "field2" => "y")) | Translated to field = 'x' AND field2 = 'y' (with automatic escaping)
|
If the dot notation is used for a column anywhere in the query ("$table.$column") then NotORM automatically creates left join to the referenced table. Even references across several tables are possible ("$table1.$table2.$column"). Referencing tables can be accessed by colon: $applications->select("COUNT(application_tag:tag_id)").
The result also supports aggregation:
$table->count("*") | Get number of rows |
$table->count("DISTINCT $column") | Get number of distinct values |
$table->sum($column) | Get minimum value |
$table->min($column) | Get minimum value |
$table->max($column) | Get maximum value |
$table->aggregation("GROUP_CONCAT($column)") | Run any aggregation function |
foreach ($table as $id => $row) | Iterate all rows in result |
$row = $db->{$tableName}[$id] | Get single row with ID $id from table $tableName (null if the row does not exist)
|
$row = $table[$id] | Get row with primary key $id from the result
|
$row = $table[array($column => $value)] | Get first row with $column equals to $value
|
$row = $table->fetch() | Get next row from the result |
$data = $row[$column] | Get data from column $column
|
$row2 = $row->$tableName | Get row from referenced table |
$table2 = $row->$tableName([$where[, $parameters[, ...]]]) | Get result from referencing table |
$table2 = $row->$tableName()->via($column) | Use non-default column (e.g. created_by)
|
foreach ($row as $column => $data) | Iterate all values in row |
count($row) | Get number of columns in row |
(string) $row | Get primary key value |
$row["author_id"] gets the numerical value of column, $row->author gets row representing the author from the table of authors.
$row->$tableName() builds "SELECT * FROM $tableName WHERE {$myTable}_id = $row[$primary]". The returned object can be customized as usual table results (with order, limit, ...) and then executed. All results are lazy and execute only a single query for each set of rows (the result is stored to memory so following modifications will not affect it).
The object passed in second argument of NotORM constructor must implement the NotORM_Structure interface:
getPrimary($table) | Get primary key of a table in $db->$table()
|
getReferencingColumn($name, $table) | Get column holding foreign key in $table[$id]->$name()
|
getReferencingTable($name, $table) | Get target table in $table[$id]->$name()
|
getReferencedColumn($name, $table) | Get column holding foreign key in $table[$id]->$name
|
getReferencedTable($name, $table) | Get table holding foreign key in $table[$id]->$name
|
getSequence($table) | Get sequence name (after insert) |
NotORM defines a structure suitable for databases with some convention (this is the default structure):
$structure = new NotORM_Structure_Convention(
$primary = 'id',
$foreign = '%s_id',
$table = '%s',
$prefix = ''
);
There is also an auto-discovery class for MySQL. It reads meta-information from the database, which slows things down (but it can be cached).
$structure = new NotORM_Structure_Discovery($pdo, $cache = null, $foreign = '%s');
See more about structure.
The object passed in third argument of NotORM constructor must implement the NotORM_Cache interface (default null stands for no cache).
load($key) | Get data stored in the cache (return null if there is no data) |
save($key, $data) | Save data to cache |
NotORM defines following caches:
new NotORM_Cache_Session | Uses $_SESSION["NotORM"]
|
new NotORM_Cache_File($filename) | Serializes to $filename
|
new NotORM_Cache_Include($filename) | Includes $filename (very fast with PHP accelerators)
|
new NotORM_Cache_Database(PDO $connection) | Uses notorm table in the database
|
new NotORM_Cache_Memcache(Memcache $memcache) | Uses NotORM. prefix in Memcache
|
new NotORM_Cache_APC | Uses NotORM. prefix in APC
|
The table used by NotORM_Cache_Database must already exist (script should not have privileges to create it anyway):
CREATE TABLE notorm (
id varchar(255) NOT NULL,
data text NOT NULL,
PRIMARY KEY (id)
)
NotORM does not escalate errors. Non-existing table produces SQL error that is reported by PDO conforming to PDO::ATTR_ERRMODE. Non-existing columns produces the same E_NOTICE as an attempt to access non-existing key in array.
NotORM uses neither repetitive queries nor joins, because they can be slow.
One of the biggest bottlenecks in communication with databases is repetitive queries. Each round-trip to send a query costs some time and sending queries in a loop is a very bad practice.
// this is a wrong approach
foreach ($pdo->query("SELECT * FROM application") as $application) {
$author = $pdo->query("SELECT * FROM author WHERE id = $application[author_id]")->fetch();
}
Joins are much better but they have drawbacks as well:
To explain the second point, consider the following query getting all applications with their tags:
SELECT application.*, tag.*
FROM application
LEFT JOIN application_tag ON application.id = application_tag.application_id
LEFT JOIN tag ON application_tag.tag_id = tag.id
ORDER BY application.id
| id | author_id | title | web | slogan | id | name |
|---|---|---|---|---|---|---|
| 1 | 11 | Adminer | http://www.adminer.org/ | Database management in single PHP file | 21 | PHP |
| 1 | 11 | Adminer | http://www.adminer.org/ | Database management in single PHP file | 22 | MySQL |
| 2 | 11 | JUSH | http://jush.sourceforge.net/ | JavaScript Syntax Highlighter | 23 | JavaScript |
| 3 | 12 | Nette | http://nettephp.com/ | Nette Framework for PHP 5 | 21 | PHP |
| 4 | 12 | Dibi | http://dibiphp.com/ | Database Abstraction Library for PHP 5 | 21 | PHP |
| 4 | 12 | Dibi | http://dibiphp.com/ | Database Abstraction Library for PHP 5 | 22 | MySQL |
Notice how both the application and tag data are transferred repetitively. This costs time and memory and it is a huge problem if you transfer long data (like article text or blobs).
NotORM uses a different approach – it sends a constant number of simple queries (one query for each table type).
foreach ($software->application()->limit(4) as $application) {
echo "$application[title]\n";
foreach ($application->application_tag() as $application_tag) {
echo "\t" . $application_tag->tag["name"] . "\n";
}
}
This code, which gets all applications and their tags, sends just three simple queries:
SELECT * FROM application LIMIT 4;
SELECT * FROM application_tag WHERE application_id IN ('1', '2', '3', '4');
SELECT * FROM tag WHERE id IN ('21', '22', '23', '24');
The volume of transferred data is minimized and the number of queries stays low no matter how many rows are processed.
This approach is also great for MySQL query cache which is deleted each time when somebody modifies any row in any table joined in a query. Query cache utilization of this approach is optimal because each table has its own query so periodic modifications of some table does not affect query cache of other queries.
Another bottleneck in a database communication is selecting columns which are not used afterwards, usually by SELECT *. First of all, NotORM has the select method which can be used to limit retrieved columns. However, this method does not need to be used if you use a cache to store the information about used columns. Take this example:
$software = new NotORM($pdo, null, new NotORM_Cache_Session);
foreach ($software->application() as $application) {
echo "$application[title]\n";
}
The first query will be SELECT * FROM application. Then NotORM stores the information about used columns to the cache and all next requests will issue SELECT id, title FROM application. If you change the script and add more columns then one extra SELECT * will be issued and all next queries will be optimal again.
Please note that the cache key is ($table, $where) and that no columns are ever removed from the cache (except the case when the cached columns would cause an error). You have to clear the cache after removing some columns from the script to get optimal queries.
NotORM uses a simple convention for table and column names by default:
| Tables | table |
|---|---|
| Primary keys | id |
| Foreign keys | table_id (target table) |
| Table prefix | (none) |
It is however possible to use any other convention – plural table names, primary key including the table name and so on. You just need to create an object implementing the NotORM_Structure interface or use a NotORM_Structure_Convention object with custom parameters:
$structure = new NotORM_Structure_Convention(
$primary = "id_%s", // id_$table
$foreign = "id_%s", // id_$table
$table = "%ss", // {$table}s
$prefix = "wp_" // wp_$table
);
$software = new NotORM($pdo, $structure);
Simple conventions can be described by constructor parameters (%1$s or first %s stands for the first method argument, %2$s for the second). Exceptions from these conventions can be defined by an extension class. Lets say that the database uses a common convention but there are columns created_by_id and modified_by_id in several tables all linking to the table user:
class UserStructure extends NotORM_Structure_Convention {
function getReferencedTable($name, $table) {
if ($name == "created_by" || $name == "modified_by") {
return "user";
}
return parent::getReferencedTable($name, $table);
}
}
$structure = new UserStructure;
Another example is a reference to parent. If there is a column parent_id referencing to the same table then the following convention allows accessing parents easily:
class ParentStructure extends NotORM_Structure_Convention {
function getReferencedTable($name, $table) {
if ($name == "parent") {
return $table;
}
}
}
There is also an auto-discovery class for MySQL >= 5 which can work with InnoDB tables in the database without any convention. It however costs some time to discover the primary and foreign keys from meta-information.
NotORM supports data modification (insert, update and delete). No data validation is performed by NotORM but all database errors are reported by the standard PDO error reporting.
$row = $db->$tableName()->insert($array) | Insert a row into table $tableName and return the inserted row
|
$row = $db->$tableName()->insert($array, ...) | Insert multiple rows by a single INSERT and return the first row
|
$row = $db->$tableName()->insert_multi(array($array, ...)) | Insert multiple rows by a single INSERT and return the number of inserted rows
|
$affected = $db->$tableName()->insert($result) | Insert all rows of the result into $tableName using INSERT ... SELECT
|
$affected = $table->update($array) | Update all rows in table result |
$affected = $table->insert_update($unique, $insert, $update) | Insert row or update if it already exists |
$affected = $table->delete() | Delete all rows in table result |
$affected = $row->update($array) | Update single row |
$affected = $row->update() | Update single row by real modifications ($row[$column] = $value or $row->$tableName = $row2)
|
$affected = $row->delete() | Delete single row |
$insert_id = $db->$tableName()->insert_id() | Get last insert ID |
$db->freeze = true | Disable persistence |
The $array parameter holds column names in keys and data in values. Values are automatically quoted, SQL literals can be passed as objects of class NotORM_Literal, for example:
$array = array(
"title" => "NotORM",
"author_id" => null,
"created" => new NotORM_Literal("NOW()"),
);
NotORM_Literal also accepts question marks and parameters: new NotORM_Literal("NOW() - INTERVAL ? DAY", $days).
Disabling persistence by freeze is useful for example before sending the data to the template.
// insert application
$application = $db->application()->insert(array(
"id" => 5, // omit or null for auto_increment
"author_id" => 11,
"title" => "NotORM",
));
$application->application_tag()->insert(array("tag_id" => 21)); // insert its tag
$application["web"] = "http://www.notorm.com/";
$application->update(); // only web will be saved, no other columns
$db->application()->insert_update(
array("id" => 5), // unique key
array("title" => "NotORM"), // insert values if the row doesn't exist
array("modified" => new NotORM_Literal("NOW()")) // update values otherwise
);
$application->delete();
This code runs following queries:
INSERT INTO application (id, author_id, title) VALUES (5, 11, 'NotORM');
INSERT INTO application_tag (application_id, tag_id) VALUES (5, 21);
UPDATE application SET web = 'http://www.notorm.com/' WHERE (id = 5);
INSERT INTO application (id, title) VALUES (5, 'NotORM') ON DUPLICATE KEY UPDATE modified = NOW();
DELETE FROM application WHERE (id = 5);
Does NotORM require primary keys in all tables?
No. If the column returned by getPrimary method does not exist in the table or if it is not included in retrieved data (specified by select method) then the returned rows are indexed by their order. Then it is not possible to reference other tables with ->() from this row.
Does NotORM support multi-column primary keys?
Yes. What NotORM does not support is multi-column foreign keys. So it is valid to define a two-column primary key in M:N table but it is not possible to use a foreign key pointing to (type, id_type) – this is rarely used. NotORM also doesn't support updating rows based on multi-column primary key. Methods getPrimary, getReferencingColumn and getReferencedColumn must return a single column.
Does NotORM automatically escape table and column names?
No, NotORM doesn't escape any identifiers (in contrast to data, which is always escaped) so it is your responsibility to escape identifier if the column or table name collides with an SQL keyword. For example if a column have name order (which is an SQL keyword) then you have to call where("`order` IS NOT NULL") for MySQL. Returned column names are however always without quotes so you always access $row["order"]. Tables are even more tricky – if the table has a name select then you have to call $db->{"`select`"}(). Some escaping can be also done in NotORM_Structure implementation. The best approach is to avoid using the SQL keywords for identifiers. If you want to sort the data based on a user supplied column then use a whitelist: if (in_array($_GET["order"], $allowedOrders)) { $result->order($_GET["order"]); }.
Does NotORM forbid some table names?
If the table name collides with PHP magic method (starting with two underscores or offsetExists, offsetGet, offsetSet, offsetUnset, jsonSerialize and getIterator) then it can be accessed as $row->__call('offsetGet'). There are no magic readable properties used by NotORM.
Are referenced data always retrived for all rows in result?
Yes. If you use $row->$tableName or $row->$tableName() then relations for all rows in result set will be retrieved. If you need the information only for some rows then you can retrieve it directly:
$first = true;
foreach ($db->application() as $application) {
if ($first) { // we want to display tags only for the first application in a list
// this would retrieve tags for all applications: $application_tags = $application->application_tag();
// this will retrieve tags only for the first application
$application_tags = $db->application_tag("application_id", $application["id"]);
// process $application_tags here
$first = false;
}
// process $application here
}
Is it possible to have more columns pointing to the same table?
Yes, it's used in the demo database – the table application has columns author_id and maintainer_id both pointing to the table author. Getting all applications maintained by some author is simple: $author->application()->via('maintainer_id'). Getting maintainer of application is slightly more involved. If you use NotORM_Structure_Discovery then you don't need to do anything and you can simply use $application->maintainer_id['name']. If you use NotORM_Structure_Convention then you need to extend this class:
class SoftwareConvention extends NotORM_Structure_Convention {
function getReferencedTable($name, $table) {
switch ($name) {
case 'maintainer': return parent::getReferencedTable('author', $table);
}
return parent::getReferencedTable($name, $table);
}
}
$software = new NotORM($connection, new SoftwareConvention);
$maintainer = $software->application[1]->maintainer;
How to create a plain array from NotORM result?
You can use iterator_to_array:
// inner call converts the rows, outer call converts the fields
array_map('iterator_to_array', iterator_to_array($db->application()));
json_encode on the NotORM result.
What about memory consumption?
NotORM stores all data retrieved from the database to memory. This is the same approach as buffered queries use (enabled by default for MySQL). To work with extremely large result sets (for example to generate Sitemaps) it is better to retrieve them in chunks for example with $table->limit(1000). Your database server will be glad too:
$limit = 1000;
$id = 0;
do {
// "WHERE id > ?" is faster than a big offset
$applications = $db->application("id > ?", $id)->order("id")->limit($limit);
foreach ($applications as $id => $application) {
// process the result here
}
} while (count($applications) == $limit);
If the page is huge with several components executing lots of different types of queries then the bottleneck is usually the number of round-trips to the database. If each query is as fast as possible then the only thing we can do to improve the performance is to reduce the number of communications with the database. NotORM allows this by deferring the queries and executing them together. All you need to do is to register a callback which will be called when the data is ready:
$db->author()->order("name")->then(function ($authors) {
foreach ($authors as $author) {
echo "$author[name]\n";
}
});
NotORM then will execute queries on the same level from all components together. So the number of round-trips to the database will decrease from total count of unique queries to the maximum component level. Level means the depth of queries that depends on its parent - so if you need authors, their applications and tags of these applications then the level is 3. In another words - if you have 50 different components of level 3 on a page, then the number of communications with the database will reduce from 150 to 3.
$table->then($callback) is a shortcut for NotORM::then($result, $callback). $table->thenForeach($callback) calls $callback($row, $id) for each row in the result.
NotORM::then() accepts variable number of arguments and it is responsible for deferring the calls. It will call $callback with all the preceding parameters once the results are ready. It makes perfect sense to call NotORM::then() only with $callback at the top level to start deferring. It also makes sense to call it with more than two parameters if you need some data together:
// starts deferring
NotORM::then(function () use ($db) {
// calls callback when the results are ready
$db->author()->order("name")->then(function ($authors) {
if (count($authors)) {
echo "Authors:\n";
foreach ($authors as $author) {
echo "$author[name]\n";
}
echo "\n";
}
});
// this output is deferred together with queries
echo "Application tags:\n";
// calls callback for each row when the results are ready
$db->application_tag()->order("application_id, tag_id")->thenForeach(function ($application_tag) {
// calls callback with both referenced rows together
NotORM::then($application_tag->application, $application_tag->tag, function ($application, $tag) {
echo "$application[title]: $tag[name]\n";
});
});
});
It is important to understand that only query execution and standard output (echo) are deferred. All other instructions are processed prior to them. This one will work as expected:
NotORM::then(function () use ($db) {
$db->author()->thenForeach(function ($author) {
echo "$author[name]\n";
});
echo "This is end.\n";
});
But this one won't:
NotORM::then(function () use ($db, $fp) {
$db->author()->thenForeach(function ($author) use ($fp) {
fwrite($fp, "$author[name]\n");
});
// this line will be written first
fwrite($fp, echo "This is end.\n");
});
It is possible to defer any code with NotORM::then($callback) but it gets tricky with multiple levels.
Deferred calls don't require anonymous functions available since PHP 5.3. This will work:
function authorsReady($authors) {
}
$db->author()->then('authorsReady');
Under development in branch then.
Object-relational mapping (ORM) systems usually require defining classes for entities (often mapping to tables) which is boring and repetitive task. Some of them can generate these classes from database (or vice versa) which is just another boring work – you have to run regeneration after each change.
ORM is also usually a wrong place for data validation – if you want consistent data then you need to validate it on the database level. Otherwise, it can get inconsistent for example after access from the database console. Most checks on the database level are simple:
varchar(40).NOT NULL.CHECK clause or by trigger.More complex checks as an e-mail validation can be processed in the form handler because they need to display the error message as close to error as possible (by JavaScript or PHP).
Administration interface to manage data in the whole database can be created with Adminer Editor for free.
ORMs also usually do not help with efficient reading of relationship data, which is the most common task in many database applications. They sometimes solve the inefficiency by data caching which is not optimal approach for two reasons:
The best approach is to efficiently get data directly from the primary storage, which is exactly what NotORM does.
© 2010 Jakub Vrána, jakub@vrana.cz